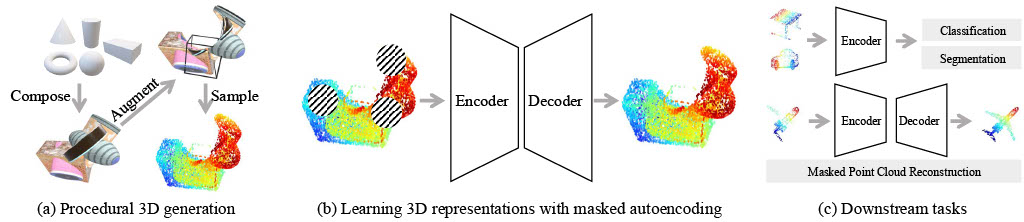
(a) Our synthetic 3D point clouds are generated by sampling, compositing, and augmenting simple primitives with procedural 3D programs. (b) We use Point-MAE as our pretraining framework to learn 3D representation from synthetic 3D shapes, dubbed Point-MAE-Zero where "Zero" underscores that we do not use any human-made 3D shapes. (c) We evaluate Point-MAE-Zero in various 3D shape understanding tasks.
TL;DR: Self-supervised 3D representation learning from procedural 3D programs performs on par with learning from ShapeNet across various downstream 3D tasks. Both outperforms training from scratch in a large margin.
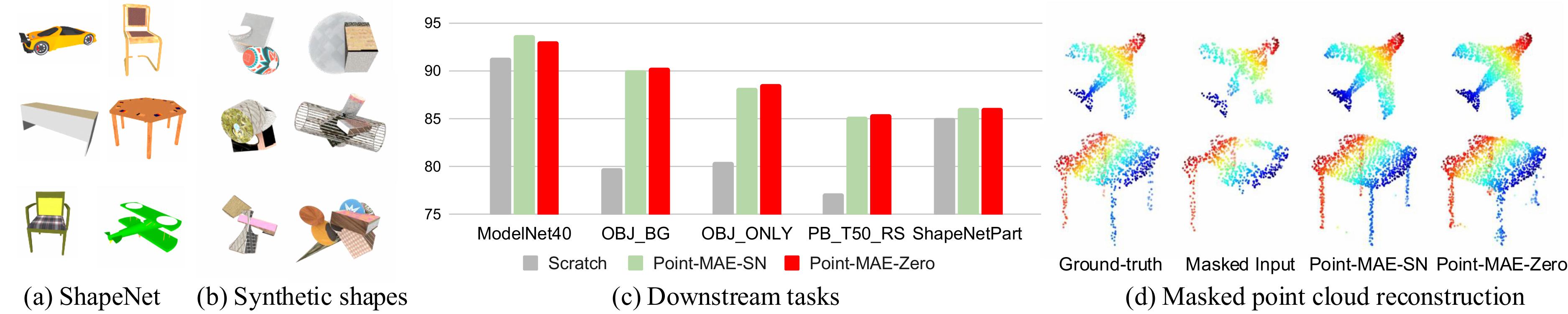
Key Insights and Findings: (a) Point-MAE-SN is trained on ShapeNet, providing semantically meaningful 3D models. (b) Point-MAE-Zero is trained on procedurally generated 3D shapes without semantic structure. (c) Point-MAE-Zero matches or outperforms Point-MAE-SN on tasks like ModelNet40, ScanObjectNN, and ShapeNetPart, significantly outperforming training from scratch.
Abstract
Self-supervised learning has emerged as a promising approach for acquiring transferable 3D representations from unlabeled 3D point clouds. Unlike 2D images, which are widely accessible, acquiring 3D assets requires specialized expertise or professional 3D scanning equipment, making it difficult to scale and raising copyright concerns. To address these challenges, we propose learning 3D representations from procedural 3D programs that automatically generate 3D shapes using simple primitives and augmentations. Remarkably, despite lacking semantic content, the 3D representations learned from this synthesized dataset perform on par with state-of-the-art representations learned from semantically recognizable 3D models (e.g., airplanes) across various downstream 3D tasks, including shape classification, part segmentation, and masked point cloud completion. Our analysis further suggests that current self-supervised learning methods primarily capture geometric structures rather than high-level semantics.
Point-MAE-Zero
Point-MAE-Zero is a self-supervised framework for learning 3D representations entirely from procedurally generated shapes, eliminating reliance on human-designed 3D models. Based on the Point-MAE architecture, it employs a masked autoencoding scheme, where 60% of input point patches are masked and reconstructed using a transformer-based encoder-decoder. The reconstruction loss is computed via the Chamfer Distance between predicted and ground-truth point patches. This approach demonstrates the potential of procedural generation for 3D representation learning, with zero human involvement beyond the initial programming.
Masked Point Cloud Completion
The goal of masked point cloud completion is to reconstruct masked points in 3D point clouds, serving as a pretext task for learning 3D representations. During pretraining, a portion of point patches (e.g., 60%) is randomly masked, with only visible patches passed to the encoder, while masked patch centers guide the decoder. After pretraining, the network can reconstruct missing points with or without guidance. Experiments on ShapeNet and procedurally generated 3D shapes show that Point-MAE-Zero, trained solely on procedurally generated data, performs comparably to Point-MAE-SN on both datasets. Both models effectively leverage symmetry to estimate missing parts and exhibit slightly better performance on in-domain data. Performance declines when guidance is removed, but representations learned through masked autoencoding capture geometric features rather than semantic content.
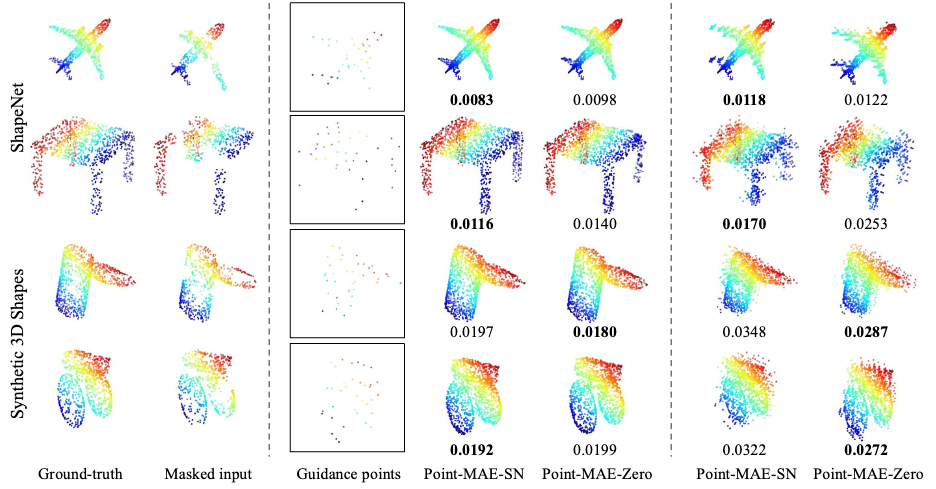
Heterogeneous ROPE sample. This figure visualizes shape completion results with Point-MAE-SN and Point-MAE-Zero on the test split of ShapeNet and procedurally synthesized 3D shapes. Left: Ground truth 3D point clouds and masked inputs with a 60% mask ratio. Middle: Shape completion results using the centers of masked input patches as guidance, following the training setup of Point-MAE. Right: Point cloud reconstructions without any guidance points. The $L_2$ Chamfer distance (lower is better) between the predicted 3D point clouds and the ground truth is displayed below each reconstruction.
Additional Visualizations
| Visualization Type | Description | Link |
|---|---|---|
| Point-MAE-SN on ShapeNet | Visualization of Point-MAE-SN on ShapeNet. | View |
| Point-MAE-SN on ShapeNet (No guidance points) | Visualization without guidance points. | View |
| Point-MAE-Zero on Synthetic Data | Visualization of Point-MAE-Zero on synthetic data. | View |
| Point-MAE-Zero on Synthetic Data (No guidance points) | Visualization without guidance points. | View |
| Point-MAE-SN on Synthetic Data | Visualization of Point-MAE-SN on synthetic data. | View |
| Point-MAE-SN on Synthetic Data (No guidance points) | Visualization without guidance points. | View |
| Point-MAE-Zero on ShapeNet | Visualization of Point-MAE-Zero on ShapeNet. | View |
| Point-MAE-Zero on ShapeNet (No guidance points) | Visualization without guidance points. | View |
Object Classification Results
In object classification, Point-MAE-Zero achieves performance comparable to Point-MAE-SN on ModelNet40, highlighting the impact of domain differences between procedurally generated shapes and clean 3D models. On ScanObjectNN, Point-MAE-Zero outperforms Point-MAE-SN across all variants, demonstrating the benefits of pretraining on diverse and procedurally synthesized 3D shapes. Both models surpass training from scratch and other self-supervised approaches. Please see our paper for more results.
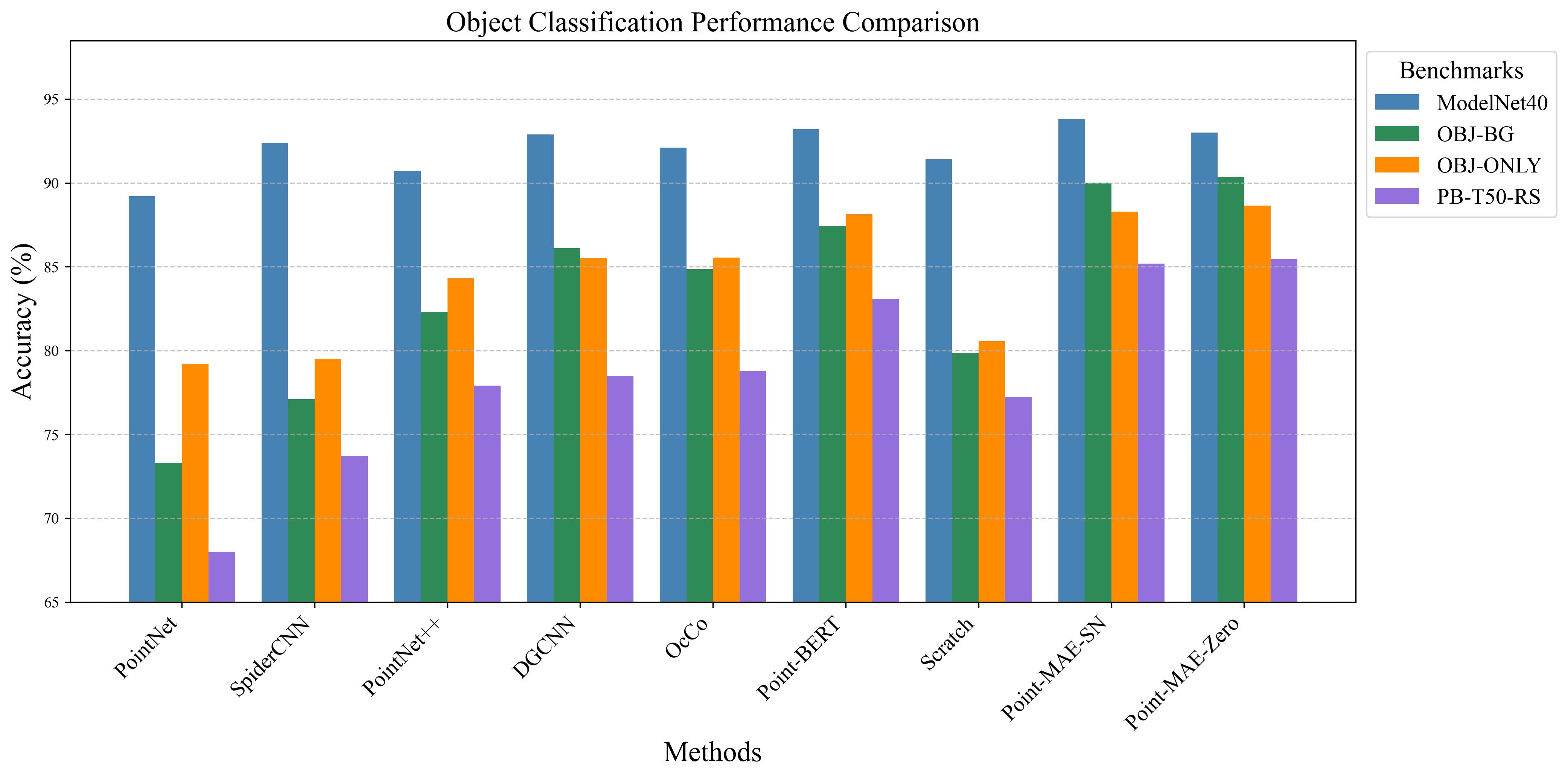
Object classification results comparing Point-MAE-Zero and Point-MAE-SN across various benchmarks.
Efficiency of Transfer Learning
The learning curves highlight the efficiency of transfer learning with Point-MAE-SN and Point-MAE-Zero. Both models converge faster and achieve higher test accuracy compared to training from scratch, a trend observed across ModelNet40 and ScanObjectNN benchmarks.
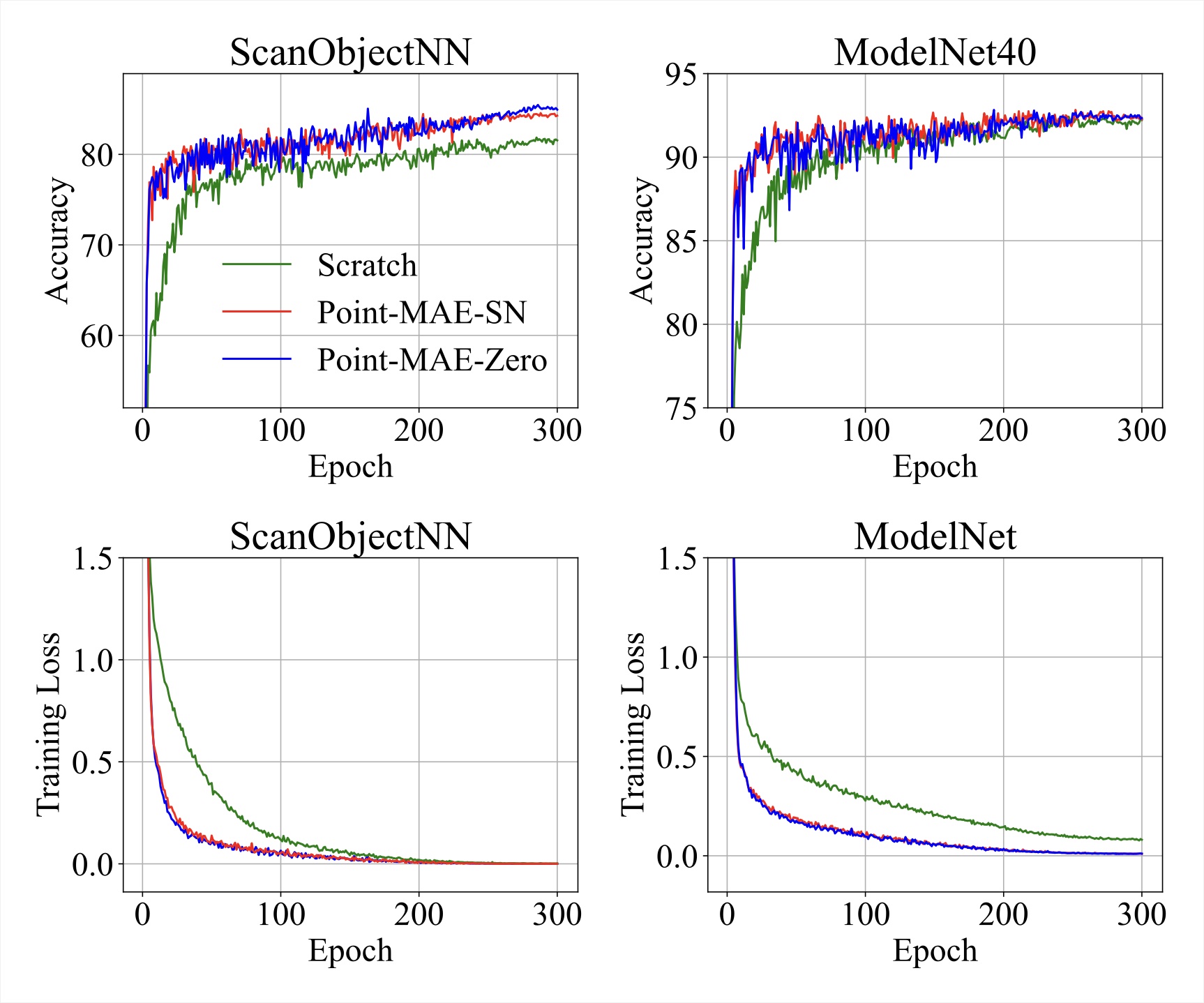
Learning curves for training from scratch, Point-MAE-SN, and Point-MAE-Zero on shape classification tasks.
t-SNE Visualization
The t-SNE visualization compares 3D shape representations from Point-MAE-SN and Point-MAE-Zero, highlighting differences before and after fine-tuning. Before fine-tuning, both models show improved separation of categories compared to training from scratch, demonstrating the effectiveness of self-supervised pretraining. After fine-tuning, the separation becomes less distinct, suggesting that high-level semantic features may not be fully learned through the masked autoencoding scheme. Structural similarities between Point-MAE-SN and Point-MAE-Zero representations suggest that both models capture comparable 3D features despite pretraining on different datasets.
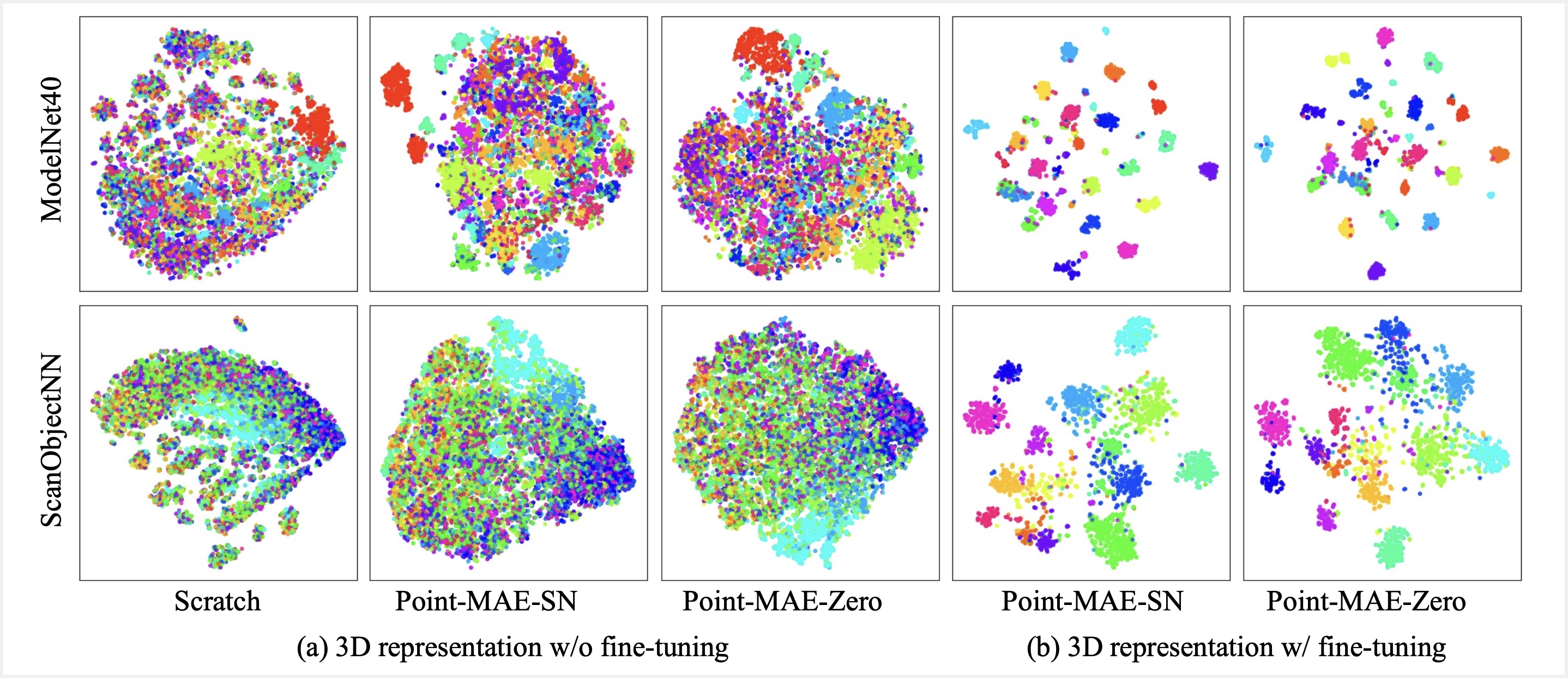
t-SNE visualization of 3D shape representations from Point-MAE-SN and Point-MAE-Zero before and after fine-tuning.
Citation
@article{chen2024learning3drepresentationsprocedural,
title={Learning 3D Representations from Procedural 3D Programs},
author={Xuweiyi Chen and Zezhou Cheng},
year={2024},
eprint={2411.17467},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.17467},
}